5种优化方法:MySQL的Like查询
在MySQL中, 关于LIKE 模糊查询可能会导致性能问题,特别是当使用通配符%开头时,因为这通常会导致全表扫描。以下用5种方法可以帮助优化 LIKE 模糊查询:合理使用索引、使用反向索引、限制扫描范围、使用缓存、使用专业工具
在MySQL中, 关于LIKE 模糊查询可能会导致性能问题,特别是当使用通配符%开头时,因为这通常会导致全表扫描。
以下用5种方法可以帮助优化 LIKE 模糊查询。

第一种:合理使用索引
前缀匹配:使用LIKE '前缀%' 的形式。这种情况MySQL能够利用索引,比如:
SELECT * FROM users WHERE username LIKE '张%'
如果 username 字段有索引,前缀匹配会用到索引。
第二种:使用反向索引
对于需要匹配后缀的情况(即 LIKE '%后缀' ),可以创建一个辅助列存储反转字符串,并基于此列进行前缀匹配。
ALTER TABLE users ADD reversed username VARCHAR(255); UPDATE users SET reversed_username = REVERSE(username); CREATE INDEX idx_reversed username ON users(reversed_username);
其实就是创建反向字符串,到底就是一种取巧,用空间换时间。
不是不能用,看情况来。
第三种:限制扫描范围
在LIKE查询中,如果可以通过其他条件进一步缩小搜索范围,请尽量加入这些条件。
SELECT * FROM users WHERE create_time >'2023-01-01' AND username LIKE '张%';
第四种:使用缓存
如果相同的查询需要频繁执行,可以考虑在应用层实施缓存策略来减少数据库负载。
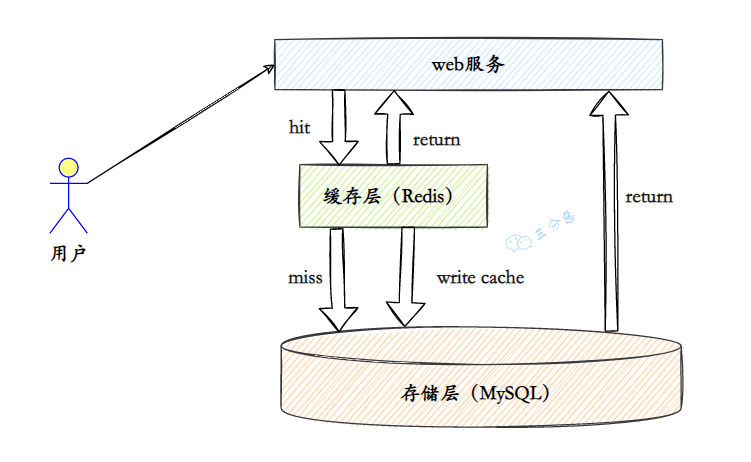
常见的比如Redis,但是这里需要注意,缓存存放的数据是很少改动的。
第五种:使用专业工具
对于非常大的数据集或者需要复杂文本处理和搜索功能,可以使用外部全文搜索引擎如Elasticsearch、Solr或者Sphinx来代替MySQL的LIKE操作。
但是我们尽量存一些关键信息,不需要把所有数据都存进去,记住他只是一个工具,能帮我们解决问题即可。
通过这些方法优化LIKE查询,可以显著提升数据库的査询性能。应根据具体场景选择合适的优化策略。
使用EXPLAIN分析查询执行计划,可以确认我们的优化效果。