如何保证分库分表后ID的全局唯一性?
我们了解了分布式存储的两个核心问题:数据冗余和数据分片,以及在传统关系型数据库中是如何解决这些问题的。当我们面临高并发的查询数据请求时,可以使用主从读写分离的方式,部署多个从库以分摊读压力。 当存储的…
我们了解了分布式存储的两个核心问题:数据冗余和数据分片,以及在传统关系型数据库中是如何解决这些问题的。当我们面临高并发的查询数据请求时,可以使用主从读写分离的方式,部署多个从库以分摊读压力。
当存储的数据量达到瓶颈时,可以将数据分片存储在多个节点上,从而降低单个存储节点的存储压力。
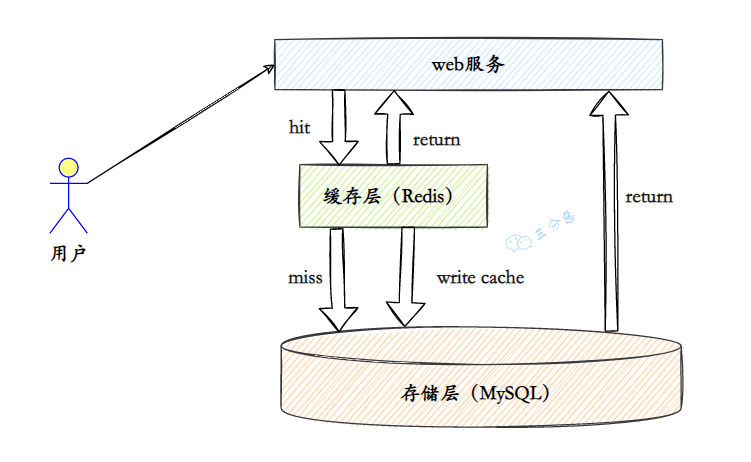
此时,我们的架构会演变成以下这种形式:

通过分库分表和主从读写分离的方式,我们成功解决了数据库的扩展性问题。然而,在数据库分库分表之后,我们在使用时也会面临一些限制。例如,查询时必须携带分区键;某些聚合类查询(如 count())的性能较差,需要借助计数器等其他解决方案来优化。此外,分库分表还带来了一个重要的问题——主键的全局唯一性。
本节中,我们将深入探讨如何在分库分表的情况下生成全局唯一的数据库主键。
数据库的主键要如何选择?
在数据库中,每一条记录都需要一个唯一的标识。这一要求源于数据库的第二范式,即每个表中都必须有一个唯一的主键,其他数据元素与主键一一对应。因此,如何选择主键成为一个关键问题。
通常,主键有两种选择方式:
使用业务字段作为主键:例如,在用户表中,可以使用手机号、电子邮件或身份证号作为主键。
使用生成的唯一 ID 作为主键:这是更常见的选择,尤其是在大部分场景下。
为什么业务字段不适合作为主键?
对于许多场景,比如评论表,很难找到一个业务字段唯一标识一条评论。同样,在用户表中,虽然看似有多个字段可以选用,但每种方案都有问题:
手机号或电子邮件:用户可能拥有多个手机号或邮箱地址,且一旦更换,所有引用的外键信息都需要同步变更,维护成本很高。
身份证号:虽然它可以唯一标识用户,但由于隐私属性,并不是所有系统都要求用户填写身份证号。此外,身份证号可能发生变更(例如,从 15 位变为 18 位),这也会导致所有相关表需要同步更新,工作量巨大。
因此,使用业务字段作为主键并不适合大多数场景。
为什么选择生成的唯一 ID?
生成的唯一 ID 具有以下优势:
唯一性:可以确保在整个系统中不重复。
稳定性:一旦生成,不会发生变更,引用更加灵活。
在单库单表的场景中,使用数据库的自增字段生成 ID 是一种简单且直观的方式。然而,当系统分库分表后,自增字段无法保证全局唯一性。
分库分表后的挑战
分库分表后,同一个逻辑表的数据分布在多个库中。此时,数据库的自增字段只能保证在单个库内唯一,无法在全局范围内唯一。例如,用户表中的两个用户可能在不同的分库中生成相同的 ID,这显然是不可接受的。
如何解决全局唯一性问题?
为了解决这个问题,我建议搭建发号器服务,用于生成全局唯一的 ID。这种方案不仅解决了分布式场景下的唯一性问题,还能保持 ID 的稳定性和高效生成,适用于大规模分布式系统的需求。
基于 Snowflake 算法搭建发号器
在我的项目经验中,我主要采用变种的 Snowflake 算法 来生成业务需要的 ID。本节的重点也是基于这个算法,解决全局唯一 ID 的问题。只要弄清楚它的实现原理,就可以用它设计一套分布式发号器。
不过,你可能会问:“既然提到全局唯一性,为什么不直接用 UUID 呢?”确实,UUID(Universally Unique Identifier,通用唯一标识符)无需依赖任何第三方系统,因此在性能和可用性方面表现不错。比如,我常用它来生成 Request ID,标记每次请求。但如果将 UUID 作为数据库主键,就会面临以下问题:
为什么不用 UUID 作为数据库主键?
缺乏单调递增性:生成的 ID 最好是有序的,而 UUID 不具备这个特点。
评论表:存储评论的详细信息,包括 ID、内容、评论人 ID、被评论内容的 ID 等,其中 ID 作为分区键。
评论列表表:存储内容 ID 和评论 ID 的对应关系,其中内容 ID 是分区键。
为什么需要有序性?
在系统设计中,ID 往往用作排序字段。以评论系统为例,假设有两个表:当获取某个内容的评论列表时,通常需要按照时间倒序排列。如果 ID 是时间上有序的,我们可以直接按评论 ID 倒序排序。而如果 ID 无序,就需要在评论列表表中额外存储一个 创建时间字段 用作排序。
存储空间浪费:假设内容 ID、评论 ID 和时间字段均占用 8 字节存储,如果引入额外的时间字段,存储空间将增加 50%。对于海量数据,这种浪费是不小的开销。
身份证号的前 6 位表示地区编号,7~14 位是出生日期;
电话号码的区号反映所属城市,手机号前三位可以区分运营商。
算法简单且易于实现。
能够生成全局唯一的 ID,且具有单调递增性。
包含一定的业务含义,可以反解出 ID 的生成时间、发号器位置等信息。
将其中的 2~3 位作为 IDC 标识,用于支持 4 或 8 个 IDC 机房。
剩余的 7~8 位作为机器 ID,支持 128~256 台机器。
减少序列号的位数,增加机器 ID 的位数,以支持单 IDC 下更多的机器。
在 ID 中加入业务 ID 字段,用于区分不同业务模块。
1 位兼容位:恒定为 0,预留以便后续扩展。
41 位时间戳:记录时间信息。
6 位 IDC 信息:支持 64 个 IDC 机房。
6 位业务标识:支持 64 个业务模块。
10 位自增序列号:每毫秒支持 1024 个 ID。
单机房内仅部署一个发号器节点,通过 KeepAlive 机制保障高可用性,因此无需更多机器 ID 位数。
业务标识字段表示具体业务模块(例如用户模块或内容模块),这样:
不同业务生成的 ID 可互相区分,避免冲突。
出现问题时,可以通过反解 ID 快速定位具体业务模块及相关上下文信息。
业务代码在生成 ID 时无需跨网络调用,性能较高。
需要更多的 机器 ID 位数来支持更多的业务服务器。
由于业务服务器数量众多,难以保证每个机器 ID 的唯一性,因此需要引入 ZooKeeper 等分布式一致性组件来确保每台机器在重启时都能获得唯一的机器 ID。
业务系统在使用发号器时需要额外的网络调用,但由于是在内网中,性能损耗较小。
这种方式可以减少机器 ID 位数,尤其是在主备模式下,只需运行一个发号器实例,此时可以完全省略机器 ID,从而将更多的位数用于自增序列号。
调整时间戳粒度:将时间戳记录的精度从毫秒调整为秒,这样在一个时间区间内可以生成多个 ID,从而改善数据分布问题。
随机化序列号起始值:在生成序列号时使用随机起始值。例如,这一秒从 21 开始,下一秒从 30 开始。这种方式能尽可能地均衡数据分布。
贴合业务特点:设计出符合自身需求的 ID 生成规则,比如调整字段分配或加入业务标识。
解决时间偏差问题:通过检测和应对时间回拨,避免生成重复 ID。
滴滴和美团 提出了基于数据库的分布式 ID 生成方案,充分利用数据库的特性,在保证全局唯一性的同时满足业务需求。
因此,虽然 UUID 是一种通用且高效的标识生成方式,但在需要有序性、节约存储空间的场景下,它并不适合作为数据库主键。而像 Snowflake 这样的算法,正好能满足这些需求。
另一个原因在于 ID 有序也会提升数据的写入性能。
我们知道 MySQL InnoDB 存储引擎使用 B+ 树存储索引数据,而主键也是一种索引。索引数据在 B+ 树中是有序排列的,就像下面这张图一样,图中 2,10,26 都是记录的 ID,也是索引数据。
这时,当插入的下一条记录的 ID 是递增的时候,比如插入 30 时,数据库只需要把它追加到后面就好了。但是如果插入的数据是无序的,比如 ID 是 13,那么数据库就要查找 13 应该插入的位置,再挪动 13 后面的数据,这就造成了多余的数据移动的开销。
我们知道,机械磁盘在执行随机写入时,需要先完成“寻道”操作,也就是移动磁头找到对应的磁道位置。这一过程耗时较长。而在顺序写入中,不需要进行寻道操作,能够显著提升索引的写入性能。因此,这也是 UUID 不适合作为数据库主键的原因之一,因为它生成的 ID 是无序的。
此外,UUID 还有另一个缺点——它缺乏业务含义。在实际场景中,很多 ID 会包含一些有意义的数据,方便解读和验证。例如:
如果生成的 ID 可以被反解,我们就能从中提取信息。例如,知道 ID 的生成时间、生成的机房位置,以及服务的具体业务。这对问题排查非常有帮助。
最后,UUID 的格式是由 32 个 16 进制字符组成的字符串,相比数值型主键,它在数据库中占用更多存储空间。如果将 UUID 用作主键,存储效率会大幅降低。
基于这些原因,UUID 的局限性使它并不适合作为数据库主键。而 Twitter 提出的 Snowflake 算法 则很好地弥补了这些缺点。它具有以下优势:
因此,Snowflake 算法不仅满足分布式系统中对 ID 的多种需求,还能优化存储和性能,是生成主键的理想选择。
Snowflake 的核心思想是将 64bit 的二进制数字分成若干部分,每一部分都存储有特定含义的数据,比如说时间戳、机器 ID、序列号等等,最终生成全局唯一的有序 ID。它的标准算法是这样的:
从上图可以看出,Snowflake 算法中 41 位的时间戳约等于
如果你的系统部署在多个机房,那么 10 位的机器 ID 可以进一步划分。例如:
12 位的序列号则表示每个节点每毫秒最多可以生成 4096 个 ID。这套设计在大多数场景下已经能够满足需求。
Snowflake 算法的改造与应用
不同公司会根据自身业务需求,对 Snowflake 算法进行定制化改造。例如:
我的发号器设计规则
以我当前使用的发号器为例,生成规则如下:
我选择这套规则的原因如下:
这种设计兼顾了系统的灵活性和扩展性,同时满足了业务多样化的需求。
了解了 Snowflake 算法 的原理后,我们可以将它工程化,用于生成业务需要的全局唯一 ID。通常来说,算法的实现方式有两种:
1. 嵌入业务代码中
一种方法是将 Snowflake 算法直接嵌入到业务代码中,也就是分布式地在业务服务器中生成 ID。这种方式的优势在于:
但是,这种方案也有一定的挑战:
2. 独立发号器服务
另一种方法是将 Snowflake 算法实现为独立服务,即独立的发号器服务。
即使需要使用机器 ID,由于发号器实例数量有限,可以将机器 ID 固定写在发号器的配置文件中,从而确保唯一性,不再需要引入第三方组件。
微博和美图等公司就是采用独立服务的方式来部署发号器的。这种方式的性能表现优异,单实例单 CPU 可达到 每秒 2 万个 ID。
Snowflake 算法设计简单巧妙,性能高效,能够生成具备全局唯一性、单调递增性和业务含义的 ID。然而,它也存在一些不足,其中最大的问题是对系统时间戳的依赖。如果系统时间出现偏差,可能会导致生成重复的 ID。
为了解决这一问题,通常的做法是:当检测到系统时钟不准确时,发号器会暂停服务,直至时钟恢复正常。此外,Snowflake 算法在某些场景下可能会导致 ID 的分布不均。例如,当发号器的 QPS 较低(每毫秒仅生成一个 ID)时,生成的 ID 序列的末位可能固定为 1。在分库分表中使用这种 ID 作为分区键时,容易导致数据分布不均。
针对这一问题,可以采取以下两种优化方法:
Snowflake 算法的改造与实践
在实际项目中,我们常会对 Snowflake 算法进行调整,以更好地满足业务需求:
其他分布式 ID 生成方案
除了 Snowflake 算法,大型公司还会根据业务特点选择其他方案。例如:
不同场景需要不同的解决方案。对你来说,多角度了解各种方法能帮助你找到适合当前业务的最佳选择。需要记住的是,方案不在多,而在于适合。真正理解背后的原理并将其落地实施,才是最重要的。没有最好的方案,只有最适合的方案。
来源:二进制跳动
原文作者:greencoatman