“MiMo?DeepSeek?GPT-5.5它不香吗?”
“Claude Opus 4.8不也出了?何必看别的?”
昨天刚好看到有人评论,让我产生一些思考,稍微整理下,仅代表个人观点,不针对任何人,说得不对勿喷!
每次有新的、尤其是那些顶流模型发布,类似评论总会如约而至。这背后隐藏着一个危险的思维惯性:把模型品牌当成了能力的绝对标尺。
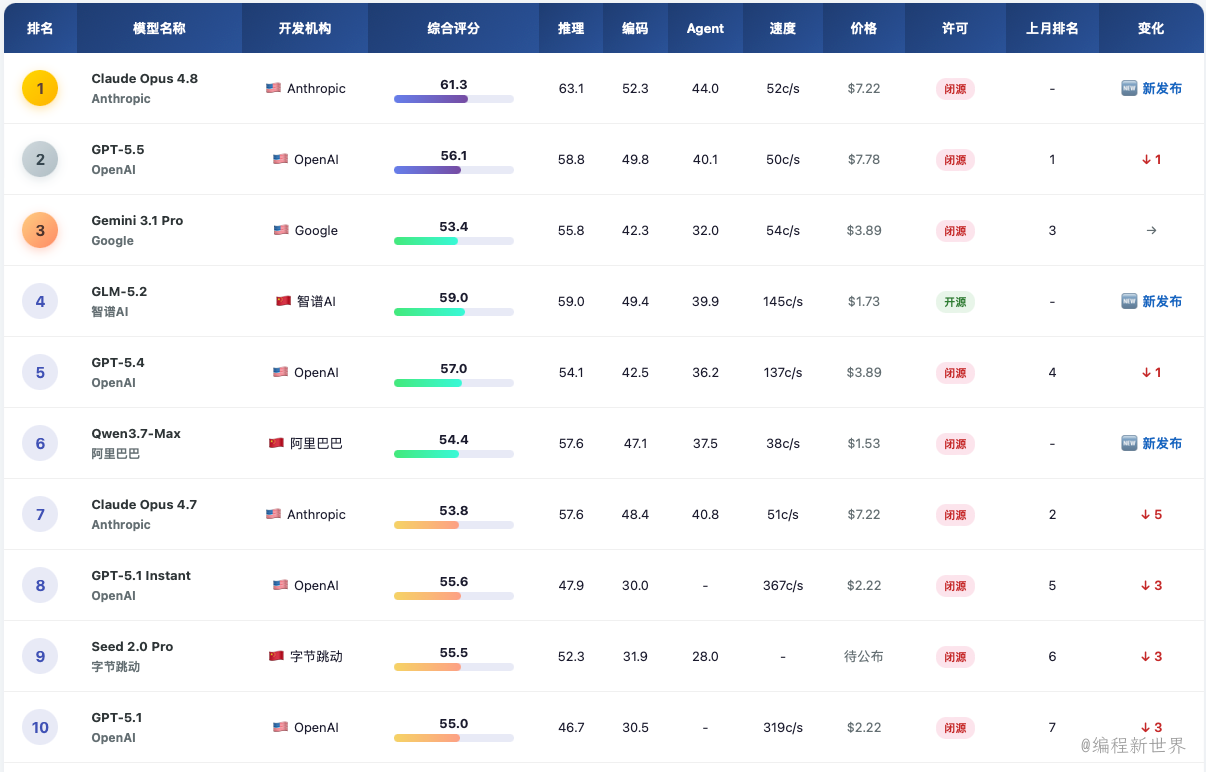
综合排名基于LLM、Stats Score、Artificial Analysis Intelligence Index、BenchLM 等权威评测
价格单位是美元/百万输出token
数据截止时间06.13
我们得承认,GPT-5.5和Claude Opus 4.8确实非常强大,是行业标杆。但“香”这个字,本身就充满了主观感受和场景依赖。今天,我们就借着剖析DeepSeek V4系列中Pro与Flash版本的区别,结合整个行业的命名惯例,来正面回应这个问题:“香”的标准,应该由你的场景来定义,而不是被营销和流行裹挟。
一、破除迷信:为什么说“闭眼入GPT/Claude”是一种奢侈的懒惰?
“香”意味着:在特定需求下,模型性能、成本、速度、可控性综合体验达到最优。 如果你不加思考地为所有场景支付顶级模型的溢价,那便不是“享受香”,而是在为“计算资源浪费”和“机会成本”买单。
根据2026年4-5月的最新行业数据,GPT-5.5和Claude Opus 4.8的定价分别为:GPT-5.5输入$10/百万tokens、输出$30/百万tokens;Claude Opus 4.7输入$15/百万tokens、输出$45/百万tokens。而DeepSeek V4 Flash的价格是输入 $0.14 /百万tokens、输出 $0.28 /百万tokens。
-
成本维度:你是“按需付费”还是“冲动消费”?
- DeepSeek V4 Flash版本的输出价格约为GPT-5.5的1/107,约为Claude Opus 4.8的1/160。如果你大部分任务只是摘要、分类、日常问答,用GPT-5.5或Claude Opus,就像开着F1赛车去小区门口取快递——油费天价,体验还未必平顺。
- Flash以近两个数量级的成本优势,提供满足日常任务的能力,这才是“真香”性价比。
-
速度与部署维度:你的业务等得起吗?
- Flash官方输出速度达81.3 tokens/秒,是Pro的2.3倍。对实时客服、批量处理而言,高速、低延迟的体验远胜于微弱的智商优势。
- Flash能本地部署(如Mac Studio),这对数据隐私敏感的企业是刚需。GPT-5.5和Claude Opus的云端依赖,在此场景下再“香”也行不通。
-
性能冗余维度:你真的需要那个“最强大脑”吗?
- DeepSeek V4 Pro在事实准确性(SimpleQA)和复杂代理任务(Terminal-Bench)上优势巨大,差距分别高达23.8点和11点。这意味着在医疗、法律、复杂自动化等高风险领域,Pro的“专业保险”价值无可替代。
- 但若只是写个普通脚本或会议纪要,GPT-5.5和Claude Opus的优势你根本感知不到。实测显示,在20个真实编码任务中,最便宜的Flash反而赢了7个第一,而Pro-Max在某些任务中思考更久、输出token多4.3倍,答案却与Flash相同甚至更差。
二、行业解码:Pro、Flash、Max……后缀里藏着什么秘密?

理解了DeepSeek的命名,我们再看看整个行业,这种“分级命名”几乎是所有主流厂商的共识。看懂这些后缀,能帮你快速定位模型定位:
| 后缀类型 | 核心定位 | 代表模型 | 一句话解读 |
|---|---|---|---|
| Ultra / Max / Pro | 能力天花板:参数量巨大、性能极致、推理强,但成本高、速度慢 | GPT-5.5 Pro、Claude Opus 4.8、Gemini 3.1 Pro | “重武器”:为最复杂的推理、科研、零容错场景而生 |
| Flash / Turbo / Lite | 效率之王:轻量化、极速、超低成本,部分可本地部署,覆盖80%日常场景 | DeepSeek V4 Flash、Gemini 1.5 Flash、Qwen3-Flash | “无人机蜂群”:以极低成本覆盖高频、大规模任务 |
| Plus / Base | 均衡主力:在性能与成本间取得平衡,适合多数通用场景 | GPT-5.5标准版、Qwen3-Plus | “多面手”:比Pro便宜,比Flash更能打 |
| Nano / Mini | 轻量部署:极致压缩,面向资源受限的边缘设备 | Gemini Nano | “微缩模型”:算力需求最低,但能力边界明显 |
不难看出,这种命名逻辑是厂商在向用户传递明确的使用说明书:Pro是秀肌肉,Flash是做产品,Plus是走量。
三、场景决策指南:你的任务属于哪个“战区”?

与其问“哪个模型最好”,不如问“我的任务属于哪个战区”。我们来看一份清晰的选型地图:
| 你的核心场景 | 推荐选择 | 核心逻辑(为什么“香”) |
|---|---|---|
| 日常开发、CRUD、简单脚本 | DeepSeek V4 Flash | 实测编码任务中表现不输Pro,成本低百倍。不选Flash是跟钱包过不去。 |
| 海量数据标注、摘要、客服RAG | DeepSeek V4 Flash | 高吞吐、超低成本(缓存命中仅$0.014/百万tokens),规模化任务的唯一解。 |
| 学术研究、竞赛编程、复杂数学 | DeepSeek V4 Pro / GPT-5.5 | 需Think Max深度推理。GPT-5.5在GPQA Diamond达93.5%,Pro在Codeforces评分达3206。 |
| 法律文书审阅、医疗咨询、金融分析 | DeepSeek V4 Pro / Claude Opus 4.8 | 零容错场景。Pro的幻觉率远低于Flash;Claude在长文档解析和严谨性上业内领先。 |
| 复杂多步Agent(8+轮工具调用) | GPT-5.5 / Claude Opus 4.7 | 实测中GPT-5.5在Terminal-Bench达82.7%,Claude Opus 4.8在SWE-bench Pro达64.3%,复杂工程落地更稳。 |
| 复杂工程级项目开发 | Claude Opus 4.8 | SWE-bench Pro 64.3%行业第一,代码生成与工程级项目落地能力断层领先。 |
四、结论:从“品牌忠诚”到“场景主权”
回到最初的问题:GPT-5.5和Claude Opus 4.8不香吗?
当然香,但那是它们擅长场景里的香。 DeepSeek的Pro和Flash版本,用极致的差异化告诉我们一个朴素的真理:
- GPT-5.5/Claude Opus是“重型战略轰炸机”,在需要顶级火力、复杂工程落地的任务中,它们无可替代,尽管代价高昂。
- DeepSeek V4 Pro是“高精度任务专家”,专攻特定高难度、低容错的复杂战场,成本远低于前者。
- DeepSeek V4 Flash则是“无人机蜂群”,以极低成本、极高效率覆盖广阔的基础作战域,在日常任务中表现惊艳。
聪明的决策者,不会用轰炸机去执行巡逻任务,也不会用无人机去轰炸地下工事。
未来,模型能力会持续趋同,真正拉开差距的是场景匹配的智慧。放弃寻找“万能神丹”,转而建立一套“场景-指标-成本”的评估框架,才是AI时代的核心竞争力。
所以,请忘掉“GPT/Claude香不香”这种笼统的问题,开始问自己:“对于我手头这个具体的、紧迫的任务,哪一个模型解决方案最‘香’? ”
愿你在AI的武器库里,不再迷茫,精准制导。
本文分析基于2026年4-5月各厂商公开的技术报告、官方定价及第三方评测数据,旨在提供选型思路,不构成对任何模型的绝对推荐。






评论
发表评论