4 月 8 日 15 点 23 分,腾讯云团队发现云 API 服务异常,并收到大批客户反馈无法登录掌握台。

据称腾讯云此次故障影响了依附云 API 的公有云服务,如云函数、文字辨认、微服务平台等,连续了近 87 分钟,期间共 1957 个客户报障。
以下为全文:
4 月 8 日 15 点 23 分,腾讯云团队收到告警信息,云 API 服务处于异常状况;随即在腾讯云工单、售后服务群以及微博等渠道开端大批涌现腾讯云掌握台登录不上的客户反馈。
经过故障定位发现,客户登录不上掌握台正是由云 API 异常所导致。云 API 是云上统一的开放接口聚集,客户可以通过 API 以编程方法管理和操控云端资源,云掌握台通过组合云 API 供给交互式的网页功效。
故障产生后,依附云 API 供给产品才能的部分公有云服务,也因为云 API 的异常涌现了无法应用的情形,比如云函数、文字辨认、微服务平台、音频内容安全、验证码等。此次故障一共连续了近 87 分钟,期间共有 1957 个客户报障。
从客户的视角来看,云服务大概可以分为数据面和掌握面,数据面承载客户自身的业务,掌握面负责操作云上不同产品。比如目前应用最普遍的 IaaS 服务根本上都是以直接面向数据面为主,掌握面仅在客户购置或须要对资源层面进行调剂操作时会涉及。此次产生故障的掌握台和云 API 是对掌握面的影响。
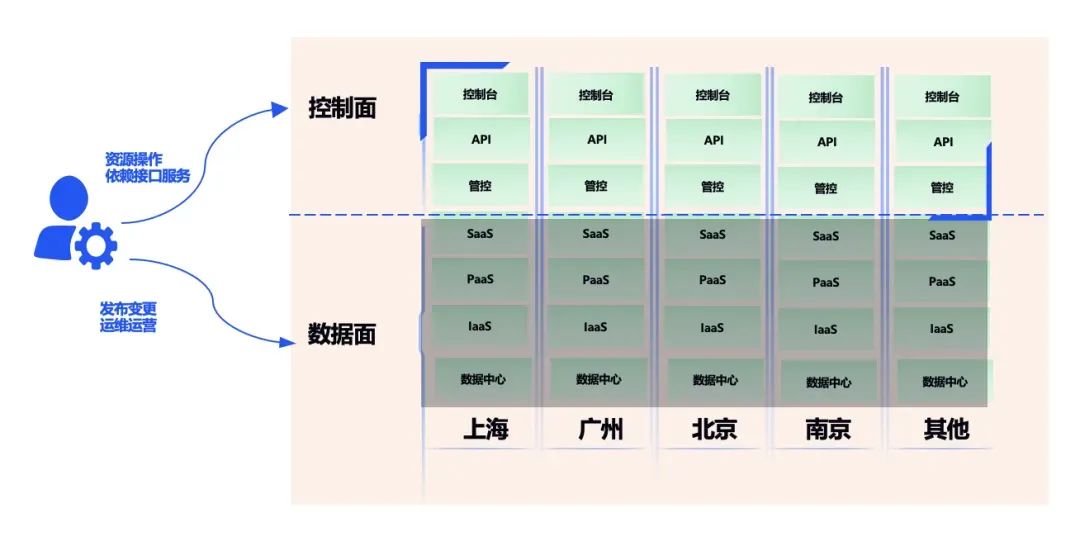
通俗来讲,如果把云服务类比为酒店,掌握台相当于酒店的前台,是一个统一的服务入口。一旦酒店前台产生故障,会导致入住、续住等管理才能不可用,但已入住的客房不受影响。
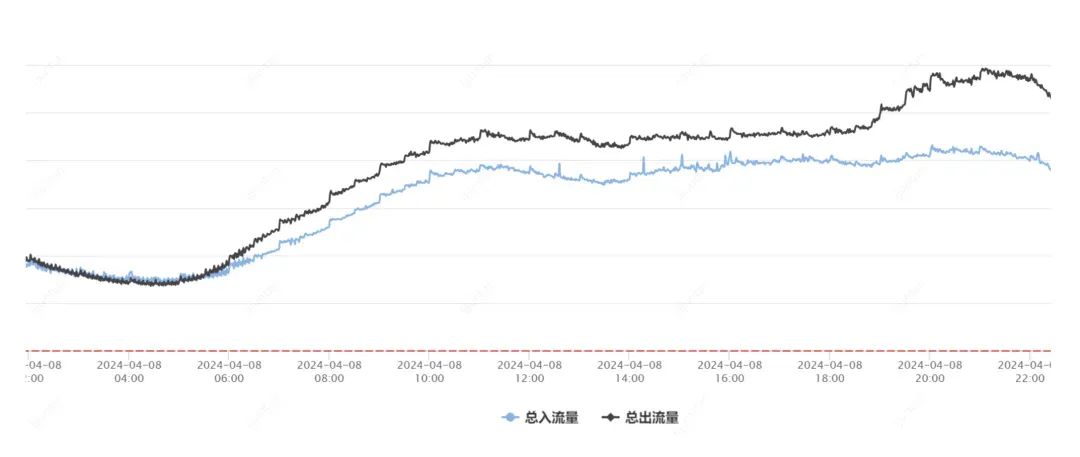
这次故障中客户已经配置好的服务器等 IaaS 资源,包含已经安排运行的业务,没有受到云 API 异常的影响。其他以非云 API 方法供给服务的 PaaS 和 SaaS 服务,处于正常服务的状况。从数据上也验证了这一点。如图 1 显示,当天全产品进出流量趋势没有显著变更。
图 1:腾讯云全产品进出流量趋势图
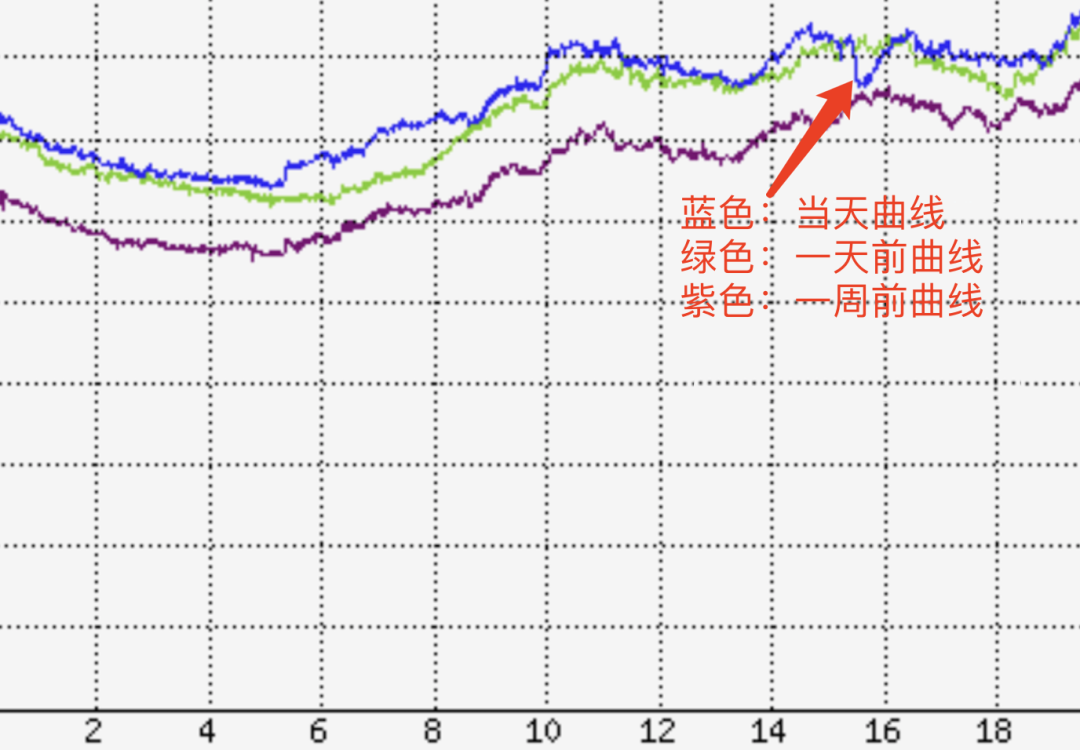
但是,用 API 供给的服务类产品(须要 “酒店前台服务 “)有不同水平的影响,比如腾讯云存储服务调用当天有显著下滑。期间售后团队协助部分客户做了业务容灾预案的实行,将受影响服务做调度以快速恢复客户的业务服务。从图 2 可以看出,当天存储服务调用有一个显著的波动。
图 2:存储服务调用数据趋势图
问题复盘
全部处置进程如下:
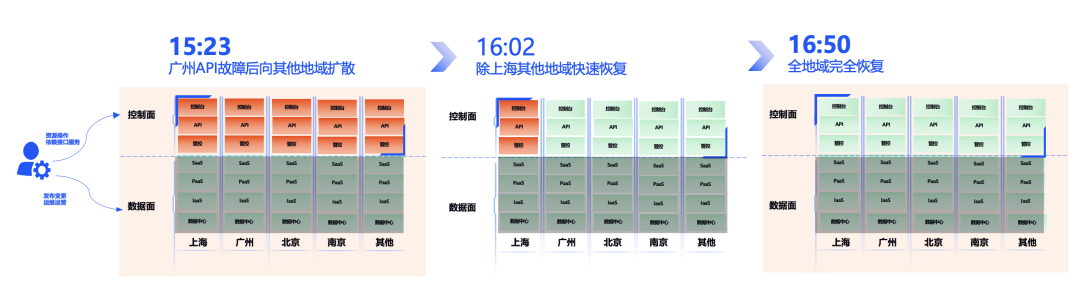
1. 15:23,监测到故障,立即履行服务的恢复,同时进行原因的排查;
2. 15:47,发现通过回滚版本没能完整恢复服务,进一步定位问题;
3. 15:57,定位出故障根因是配置数据涌现毛病,紧迫设计数据修复计划;
4. 16:02,对全地区进行数据修复工作,API 服务逐地区恢复中;
5. 16:05,观测到除上海外的地区 API 服务均已恢复,进一步定位上海地区的恢复问题;
6. 16:25,定位到上海的技巧组件存在 API 循环依附问题,决议通过流量调度至其他地区来恢复;
7. 16:45,观测到上海地区恢复了,此时 API 和依附 API 的 PaaS 服务彻底恢复,但掌握台流量剧增,按九倍容量进行了扩容;
8. 16:50,要求量逐渐恢复到正常水平,业务稳固运行,掌握台服务全体恢复;
9. 17:45,连续视察一小时,未发现问题,按预案处置进程完毕。
故障的原因是云 API 服务新版本向前兼容性斟酌不够和配置数据灰度机制不足的问题。
本次 API 升级进程中,由于新版本的接口协定产生了变更,在后台宣布新版本之后对于旧版本前端传来的数据处置逻辑异常,导致生成了一条毛病的配置数据,由于灰度机制不足导致异常数据快速扩散到了全网地区,造成整体 API 应用异常。
产生故障后,依照尺度回滚计划将服务后台和配置数据同时回滚到旧版本,并重启 API 后台服务,但此时因为承载 API 服务的容器平台也依附 API 服务才能供给调度才能,即产生了循环依附,导致服务无法主动拉起。通过运维手工启动方法才使 API 服务重启,完成全部故障恢复。
改良办法
综合清点这次故障,最根本的原因是在版本变革进程中,没有有效履行沙箱验证和预案演练,裸露了在变革管理上的不足,接下来将从以下几个方面快速进行改良和完美,以减少故障的影响规模和影响时长。
第一,晋升体系韧性
1、定期履行预定的变革策略模仿演练,确保在真实故障产生时,能够快速切换到恢复模式,最小化服务中止时光。
2、优化服务安排架构,通过火层架构、代码审查和监控等手腕, 避免 API 服务中潜在的循环依附问题。
3、供给 API 服务逃生通道,当故障产生时,可供调用方快速切换。
第二,强化变革管理与掩护办法
1、完美主动化测试用例库,在体系变革前通过沙箱环境对变革内容进行严厉验证。
2、实行灰度宣布策略,逐步推广新功效或配置更改,按集群、可用区、地区逐步生效,以便在发现问题时能够快速回滚。
3、引入异常主动熔断机制,当检测到体系异常时,能够立即中止变革进程。
第三,加强故障响应与沟通才能
1、对故障处置流程进行全面升级,确保实时更新故障处置进度和预计恢复时光点,晋升故障报告宣布效力。
2、在对外宣布的故障通知中,清楚论述受影响的业务规模、故障根因及预计修复时长,坚持透明度。
3、优化腾讯云健康状况看板(StatusPage)的信息展现逻辑,解除对云 API 等云服务的依附,通过引入缓存和容灾机制,确保即使在云服务涌现故障时,能精确、及时地传递故障信息。
References
https://mp.weixin.qq.com/s/2e2ovuwDrmwlu-vW0cKqcA
最后插播一条广告:长按辨认二维码,欢迎报名加入 4.20 武汉源创会!

热点文章