点击上方蓝字关注我们IT 咖啡馆,摸索无穷可能! 恭喜你发现了这个宝藏,这里你会发现优质的开源项目、IT知识和有趣的内容。 应用AI来生成一部分代码比拟常见,那你斟酌过让AI完成全部项目吗? 今天我们…
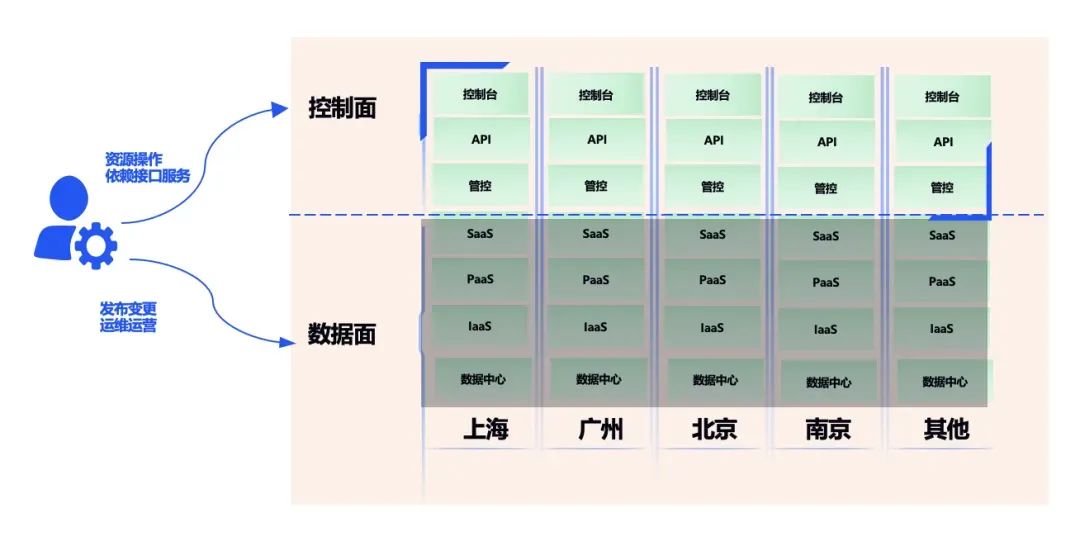
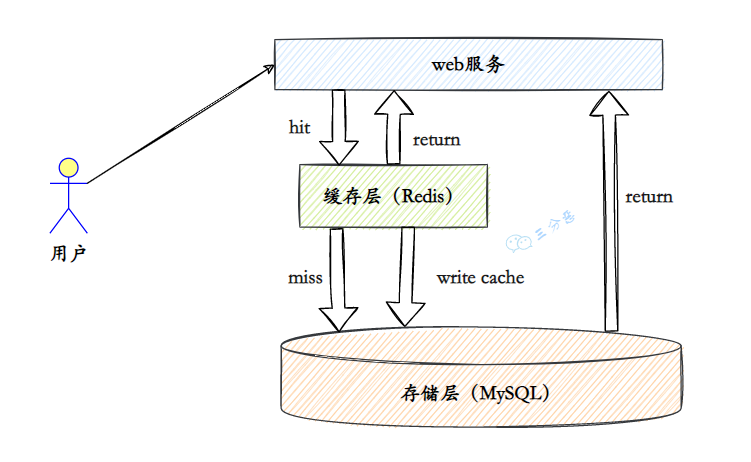
腾讯云就 4 月 8 日故障宣布了复盘及情形解释。4 月 8 日 15 点 23 分,腾讯云团队发现云 API 服务异常,并收到大批客户反馈无法登录掌握台。 据称腾讯云此次故障影响了依附云 API …
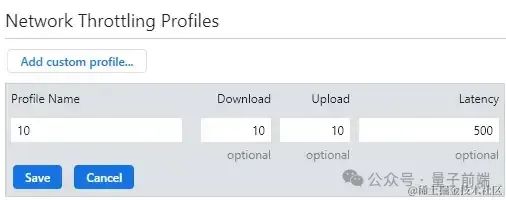
文章起源于稀土掘金技巧社区——敲代码的彭于晏1. 配置阅读器网络速度首先配置阅读器网络速度,使现象更显著。 打开chrome掌握台(按下F12),选择No Throttling,并在Custom中选择…
-

-
-

-
-

-

-
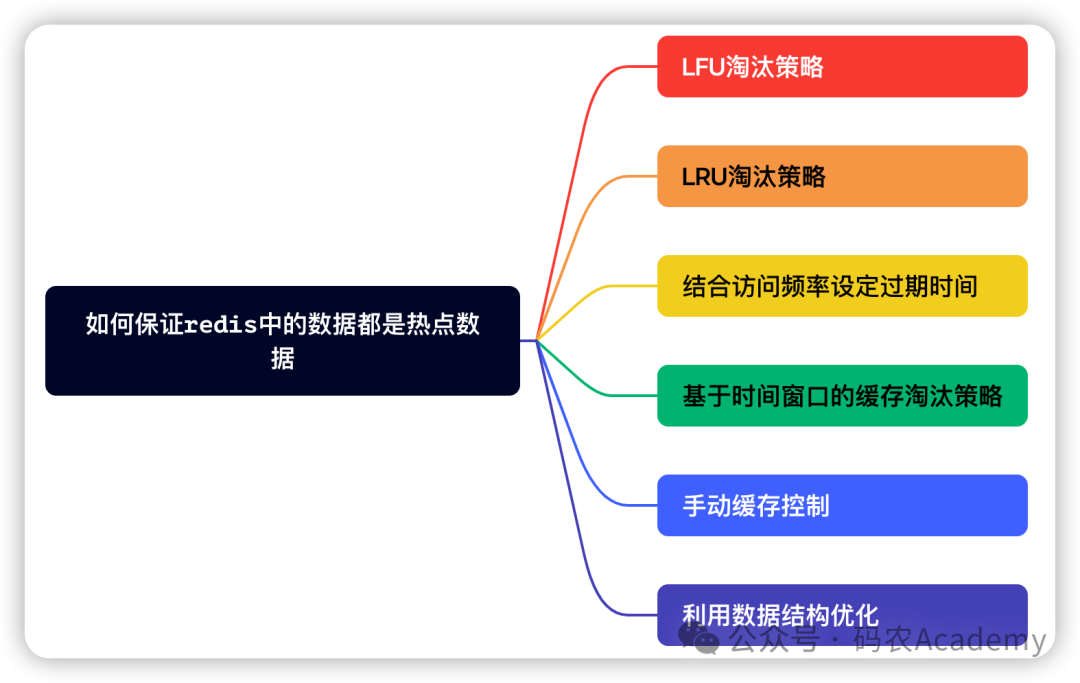
-
-
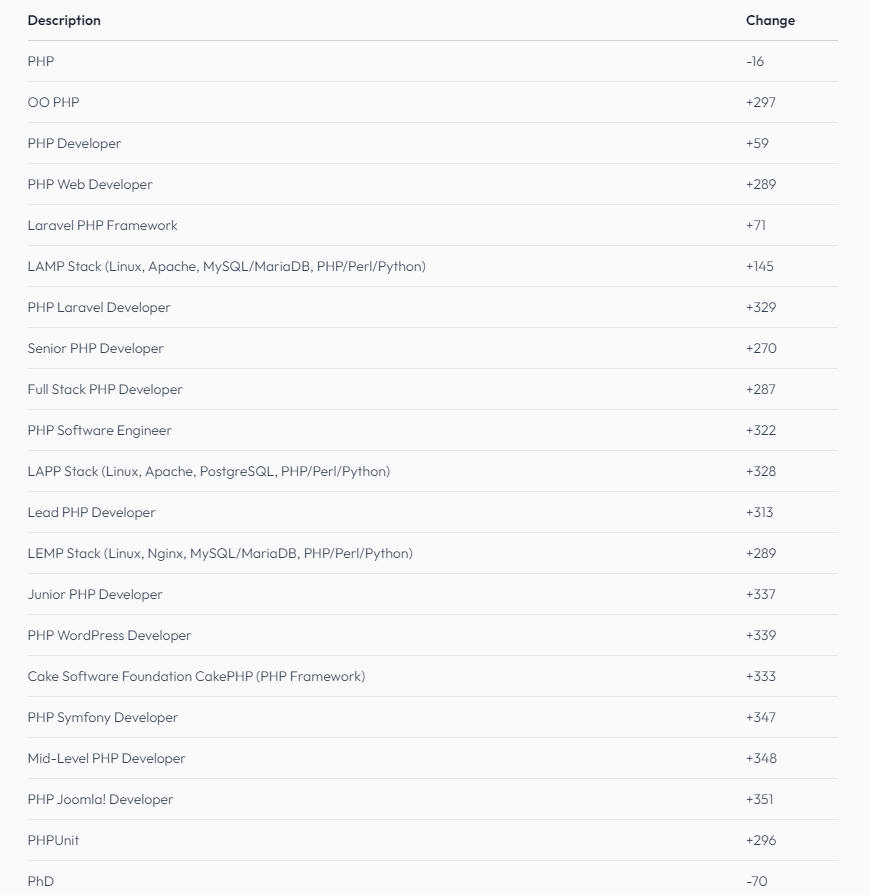 PHP死了吗?2024年的使用统计和市场份额
PHP死了吗?2024年的使用统计和市场份额介绍 由于人工智能,我们现在处于一个新的盘算时期,PHP,一种近30年历史的脚本语言的突起无法阻拦。现在比以往任何时候都更须要稳固的生态体系,而不是不断的戏剧性和分歧,以构建下一代胜利的产品。让我…
-