全网最强秒杀系统架构解密,不是所有的秒杀都是秒杀!!
实践出真知,冰河用亲身经历告诉你如何设计一个秒杀系统架构:从电商系统架构到秒杀系统、从高并发“黑科技”与致胜奇招到服务器硬件优化,全方位立体掌握秒杀系统架构!!
大家好,我是冰河~~
很多小伙伴反馈说,高并发专题学了那么久,但是,在真正做项目时,仍然不知道如何下手处理高并发业务场景!甚至很多小伙伴仍然停留在只是简单的提供接口(CRUD)阶段,不知道学习的并发知识如何运用到实际项目中,就更别提如何构建高并发系统了!
究竟什么样的系统算是高并发系统?今天,我们就一起解密高并发业务场景下典型的秒杀系统的架构,结合高并发专题下的其他文章,学以致用。
电商系统架构
在电商领域,存在着典型的秒杀业务场景,那何谓秒杀场景呢。简单的来说就是一件商品的购买人数远远大于这件商品的库存,而且这件商品在很短的时间内就会被抢购一空。 比如每年的618、双11大促,小米新品促销等业务场景,就是典型的秒杀业务场景。
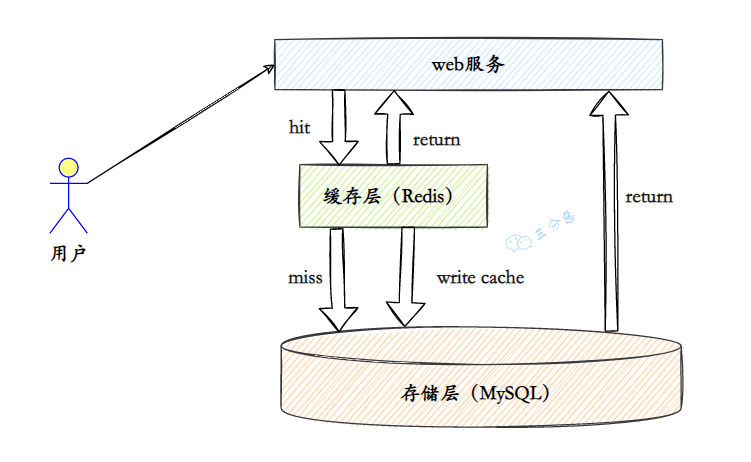
我们可以将电商系统的架构简化成下图所示。

由图所示,我们可以简单的将电商系统的核心层分为:负载均衡层、应用层和持久层。接下来,我们就预估下每一层的并发量。
假如负载均衡层使用的是高性能的Nginx,则我们可以预估Nginx最大的并发度为:10W+,这里是以万为单位。
假设应用层我们使用的是Tomcat,而Tomcat的最大并发度可以预估为800左右,这里是以百为单位。
假设持久层的缓存使用的是Redis,数据库使用的是MySQL,MySQL的最大并发度可以预估为1000左右,以千为单位。Redis的最大并发度可以预估为5W左右,以万为单位。
所以,负载均衡层、应用层和持久层各自的并发度是不同的,那么,为了提升系统的总体并发度和缓存,我们通常可以采取哪些方案呢?
(1)系统扩容
系统扩容包括垂直扩容和水平扩容,增加设备和机器配置,绝大多数的场景有效。
(2)缓存
本地缓存或者集中式缓存,减少网络IO,基于内存读取数据。大部分场景有效。
(3)读写分离
采用读写分离,分而治之,增加机器的并行处理能力。
秒杀系统的特点
对于秒杀系统来说,我们可以从业务和技术两个角度来阐述其自身存在的一些特点。
秒杀系统的业务特点
这里,我们可以使用12306网站来举例,每年春运时,12306网站的访问量是非常大的,但是网站平时的访问量却是比较平缓的,也就是说,每年春运时节,12306网站的访问量会出现瞬时突增的现象。
再比如,小米秒杀系统,在上午10点开售商品,10点前的访问量比较平缓,10点时同样会出现并发量瞬时突增的现象。
所以,秒杀系统的流量和并发量我们可以使用下图来表示。
由图可以看出,秒杀系统的并发量存在瞬时凸峰的特点,也叫做流量突刺现象。
我们可以将秒杀系统的特点总结如下。
(1)限时、限量、限价
在规定的时间内进行;秒杀活动中商品的数量有限;商品的价格会远远低于原来的价格,也就是说,在秒杀活动中,商品会以远远低于原来的价格出售。
例如,秒杀活动的时间仅限于某天上午10点到10点半,商品数量只有10万件,售完为止,而且商品的价格非常低,例如:1元购等业务场景。
限时、限量和限价可以单独存在,也可以组合存在。
(2)活动预热
需要提前配置活动;活动还未开始时,用户可以查看活动的相关信息;秒杀活动开始前,对活动进行大力宣传。
(3)持续时间短
购买的人数数量庞大;商品会迅速售完。
在系统流量呈现上,就会出现一个突刺现象,此时的并发访问量是非常高的,大部分秒杀场景下,商品会在极短的时间内售完。
秒杀系统的技术特点
我们可以将秒杀系统的技术特点总结如下。
(1)瞬时并发量非常高
大量用户会在同一时间抢购商品;瞬间并发峰值非常高。
(2)读多写少
系统中商品页的访问量巨大;商品的可购买数量非常少;库存的查询访问数量远远大于商品的购买数量。
在商品页中往往会加入一些限流措施,例如早期的秒杀系统商品页会加入验证码来平滑前端对系统的访问流量,近期的秒杀系统商品详情页会在用户打开页面时,提示用户登录系统。这都是对系统的访问进行限流的一些措施。
(3)流程简单
秒杀系统的业务流程一般比较简单;总体上来说,秒杀系统的业务流程可以概括为:下单减库存。
秒杀三阶段
通常,从秒杀开始到结束,往往会经历三个阶段:
准备阶段:这个阶段也叫作系统预热阶段,此时会提前预热秒杀系统的业务数据,往往这个时候,用户会不断刷新秒杀页面,来查看秒杀活动是否已经开始。在一定程度上,通过用户不断刷新页面的操作,可以将一些数据存储到Redis中进行预热。
秒杀阶段:这个阶段主要是秒杀活动的过程,会产生瞬时的高并发流量,对系统资源会造成巨大的冲击,所以,在秒杀阶段一定要做好系统防护。
结算阶段: 完成秒杀后的数据处理工作,比如数据的一致性问题处理,异常情况处理,商品的回仓处理等。
针对这种短时间内大流量的系统来说,就不太适合使用系统扩容了,因为即使系统扩容了,也就是在很短的时间内会使用到扩容后的系统,大部分时间内,系统无需扩容即可正常访问。 那么,我们可以采取哪些方案来提升系统的秒杀性能呢?
秒杀系统方案
针对秒杀系统的特点,我们可以采取如下的措施来提升系统的性能。
(1)异步解耦
将整体流程进行拆解,核心流程通过队列方式进行控制。
(2)限流防刷
控制网站整体流量,提高请求的门槛,避免系统资源耗尽。
(3)资源控制
将整体流程中的资源调度进行控制,扬长避短。
由于应用层能够承载的并发量比缓存的并发量少很多。所以,在高并发系统中,我们可以直接使用OpenResty由负载均衡层访问缓存,避免了调用应用层的性能损耗。大家可以到https://openresty.org/cn/来了解有关OpenResty更多的知识。同时,由于秒杀系统中,商品数量比较少,我们也可以使用动态渲染技术,CDN技术来加速网站的访问性能。
如果在秒杀活动开始时,并发量太高时,我们可以将用户的请求放入队列中进行处理,并为用户弹出排队页面。
注:图片来自魅族
秒杀系统时序图
网上很多的秒杀系统和对秒杀系统的解决方案,并不是真正的秒杀系统,他们采用的只是同步处理请求的方案,一旦并发量真的上来了,他们所谓的秒杀系统的性能会急剧下降。我们先来看一下秒杀系统在同步下单时的时序图。
同步下单流程
1.用户发起秒杀请求
在同步下单流程中,首先,用户发起秒杀请求。商城服务需要依次执行如下流程来处理秒杀请求的业务。
(1)识别验证码是否正确
商城服务判断用户发起秒杀请求时提交的验证码是否正确。
(2)判断活动是否已经结束
验证当前秒杀活动是否已经结束。
(3)验证访问请求是否处于黑名单
在电商领域中,存在着很多的恶意竞争,也就是说,其他商家可能会通过不正当手段来恶意请求秒杀系统,占用系统大量的带宽和其他系统资源。此时,就需要使用风控系统等实现黑名单机制。为了简单,也可以使用拦截器统计访问频次实现黑名单机制。
(4)验证真实库存是否足够
系统需要验证商品的真实库存是否足够,是否能够支持本次秒杀活动的商品库存量。
(5)扣减缓存中的库存
在秒杀业务中,往往会将商品库存等信息存放在缓存中,此时,还需要验证秒杀活动使用的商品库存是否足够,并且需要扣减秒杀活动的商品库存数量。
(6)计算秒杀的价格
由于在秒杀活动中,商品的秒杀价格和商品的真实价格存在差异,所以,需要计算商品的秒杀价格。
注意:如果在秒杀场景中,系统涉及的业务更加复杂的话,会涉及更多的业务操作,这里,我只是列举出一些常见的业务操作。
2.提交订单
(1)订单入口
将用户提交的订单信息保存到数据库中。
(2)扣减真实库存
订单入库后,需要在商品的真实库存中将本次成功下单的商品数量扣除。
如果我们使用上述流程开发了一个秒杀系统,当用户发起秒杀请求时,由于系统每个业务流程都是串行执行的,整体上系统的性能不会太高,当并发量太高时,我们会为用户弹出下面的排队页面,来提示用户进行等待。
注:图片来自魅族
此时的排队时间可能是15秒,也可能是30秒,甚至是更长时间。这就存在一个问题:在用户发起秒杀请求到服务器返回结果的这段时间内,客户端和服务器之间的连接不会被释放,这就会占大量占用服务器的资源。
网上很多介绍如何实现秒杀系统的文章都是采用的这种方式,那么,这种方式能做秒杀系统吗?答案是可以做,但是这种方式支撑的并发量并不是太高。此时,有些网友可能会问:我们公司就是这样做的秒杀系统啊!上线后一直在用,没啥问题啊!我想说的是:使用同步下单方式确实可以做秒杀系统,但是同步下单的性能不会太高。之所以你们公司采用同步下单的方式做秒杀系统没出现大的问题,那是因为你们的秒杀系统的并发量没达到一定的量级,也就是说,你们的秒杀系统的并发量其实并不高。
所以,很多所谓的秒杀系统,存在着秒杀的业务,但是称不上真正的秒杀系统,原因就在于他们使用的是同步的下单流程,限制了系统的并发流量。之所以上线后没出现太大的问题,是因为系统的并发量不高,不足以压死整个系统。
如果12306、淘宝、天猫、京东、小米等大型商城的秒杀系统是这么玩的话,那么,他们的系统迟早会被玩死,他们的系统工程师不被开除才怪!所以,在秒杀系统中,这种同步处理下单的业务流程的方案是不可取的。
以上就是同步下单的整个流程操作,如果下单流程更加复杂的话,就会涉及到更多的业务操作。
异步下单流程
既然同步下单流程的秒杀系统称不上真正的秒杀系统,那我们就需要采用异步的下单流程了。异步的下单流程不会限制系统的高并发流量。
1.用户发起秒杀请求
用户发起秒杀请求后,商城服务会经过如下业务流程。
(1)检测验证码是否正确
用户发起秒杀请求时,会将验证码一同发送过来,系统会检验验证码是否有效,并且是否正确。
(2)是否限流
系统会对用户的请求进行是否限流的判断,这里,我们可以通过判断消息队列的长度来进行判断。因为我们将用户的请求放在了消息队列中,消息队列中堆积的是用户的请求,我们可以根据当前消息队列中存在的待处理的请求数量来判断是否需要对用户的请求进行限流处理。
例如,在秒杀活动中,我们出售1000件商品,此时在消息队列中存在1000个请求,如果后续仍然有用户发起秒杀请求,则后续的请求我们可以不再处理,直接向用户返回商品已售完的提示。
所以,使用限流后,我们可以更快的处理用户的请求和释放连接的资源。
(3)发送MQ
用户的秒杀请求通过前面的验证后,我们就可以将用户的请求参数等信息发送到MQ中进行异步处理,同时,向用户响应结果信息。在商城服务中,会有专门的异步任务处理模块来消费消息队列中的请求,并处理后续的异步流程。
在用户发起秒杀请求时,异步下单流程比同步下单流程处理的业务操作更少,它将后续的操作通过MQ发送给异步处理模块进行处理,并迅速向用户返回响应结果,释放请求连接。
2.异步处理
我们可以将下单流程的如下操作进行异步处理。
(1)判断活动是否已经结束
(2)判断本次请求是否处于系统黑名单,为了防止电商领域同行的恶意竞争可以为系统增加黑名单机制,将恶意的请求放入系统的黑名单中。可以使用拦截器统计访问频次来实现。
(3)扣减缓存中的秒杀商品的库存数量。
(4)生成秒杀Token,这个Token是绑定当前用户和当前秒杀活动的,只有生成了秒杀Token的请求才有资格进行秒杀活动。
这里我们引入了异步处理机制,在异步处理中,系统使用多少资源,分配多少线程来处理相应的任务,是可以进行控制的。
3.短轮询查询秒杀结果
这里,可以采取客户端短轮询查询是否获得秒杀资格的方案。例如,客户端可以每隔3秒钟轮询请求服务器,查询是否获得秒杀资格,这里,我们在服务器的处理就是判断当前用户是否存在秒杀Token,如果服务器为当前用户生成了秒杀Token,则当前用户存在秒杀资格。否则继续轮询查询,直到超时或者服务器返回商品已售完或者无秒杀资格等信息为止。
采用短轮询查询秒杀结果时,在页面上我们同样可以提示用户排队处理中,但是此时客户端会每隔几秒轮询服务器查询秒杀资格的状态,相比于同步下单流程来说,无需长时间占用请求连接。
此时,可能会有网友会问:采用短轮询查询的方式,会不会存在直到超时也查询不到是否具有秒杀资格的状态呢?答案是:有可能! 这里我们试想一下秒杀的真实场景,商家参加秒杀活动本质上不是为了赚钱,而是提升商品的销量和商家的知名度,吸引更多的用户来买自己的商品。所以,我们不必保证用户能够100%的查询到是否具有秒杀资格的状态。
4.秒杀结算
(1)验证下单Token
客户端提交秒杀结算时,会将秒杀Token一同提交到服务器,商城服务会验证当前的秒杀Token是否有效。
(2)加入秒杀购物车
商城服务在验证秒杀Token合法并有效后,会将用户秒杀的商品添加到秒杀购物车。
5.提交订单
(1)订单入库
将用户提交的订单信息保存到数据库中。
(2)删除Token
秒杀商品订单入库成功后,删除秒杀Token。
这里大家可以思考一个问题:我们为什么只在异步下单流程的粉色部分采用异步处理,而没有在其他部分采取异步削峰和填谷的措施呢?
这是因为在异步下单流程的设计中,无论是在产品设计上还是在接口设计上,我们在用户发起秒杀请求阶段对用户的请求进行了限流操作,可以说,系统的限流操作是非常前置的。在用户发起秒杀请求时进行了限流,系统的高峰流量已经被平滑解决了,再往后走,其实系统的并发量和系统流量并不是非常高了。
所以,网上很多的文章和帖子中在介绍秒杀系统时,说是在下单时使用异步削峰来进行一些限流操作,那都是在扯淡! 因为下单操作在整个秒杀系统的流程中属于比较靠后的操作了,限流操作一定要前置处理,在秒杀业务后面的流程中做限流操作是没啥卵用的。
高并发“黑科技”与致胜奇招
假设,在秒杀系统中我们使用Redis实现缓存,假设Redis的读写并发量在5万左右。我们的商城秒杀业务需要支持的并发量在100万左右。如果这100万的并发全部打入Redis中,Redis很可能就会挂掉,那么,我们如何解决这个问题呢?接下来,我们就一起来探讨这个问题。
在高并发的秒杀系统中,如果采用Redis缓存数据,则Redis缓存的并发处理能力是关键,因为很多的前缀操作都需要访问Redis。而异步削峰只是基本的操作,关键还是要保证Redis的并发处理能力。
解决这个问题的关键思想就是:分而治之,将商品库存分开放。
暗度陈仓
我们在Redis中存储秒杀商品的库存数量时,可以将秒杀商品的库存进行“分割”存储来提升Redis的读写并发量。
例如,原来的秒杀商品的id为10001,库存为1000件,在Redis中的存储为(10001, 1000),我们将原有的库存分割为5份,则每份的库存为200件,此时,我们在Redia中存储的信息为(10001_0, 200),(10001_1, 200),(10001_2, 200),(10001_3, 200),(10001_4, 200)。
此时,我们将库存进行分割后,每个分割后的库存使用商品id加上一个数字标识来存储,这样,在对存储商品库存的每个Key进行Hash运算时,得出的Hash结果是不同的,这就说明,存储商品库存的Key有很大概率不在Redis的同一个槽位中,这就能够提升Redis处理请求的性能和并发量。
分割库存后,我们还需要在Redis中存储一份商品id和分割库存后的Key的映射关系,此时映射关系的Key为商品的id,也就是10001,Value为分割库存后存储库存信息的Key,也就是10001_0,10001_1,10001_2,10001_3,10001_4。在Redis中我们可以使用List来存储这些值。
在真正处理库存信息时,我们可以先从Redis中查询出秒杀商品对应的分割库存后的所有Key,同时使用AtomicLong来记录当前的请求数量,使用请求数量对从Redia中查询出的秒杀商品对应的分割库存后的所有Key的长度进行求模运算,得出的结果为0,1,2,3,4。再在前面拼接上商品id就可以得出真正的库存缓存的Key。此时,就可以根据这个Key直接到Redis中获取相应的库存信息。
移花接木
在高并发业务场景中,我们可以直接使用Lua脚本库(OpenResty)从负载均衡层直接访问缓存。
这里,我们思考一个场景:如果在秒杀业务场景中,秒杀的商品被瞬间抢购一空。此时,用户再发起秒杀请求时,如果系统由负载均衡层请求应用层的各个服务,再由应用层的各个服务访问缓存和数据库,其实,本质上已经没有任何意义了,因为商品已经卖完了,再通过系统的应用层进行层层校验已经没有太多意义了!!而应用层的并发访问量是以百为单位的,这又在一定程度上会降低系统的并发度。
为了解决这个问题,此时,我们可以在系统的负载均衡层取出用户发送请求时携带的用户id,商品id和秒杀活动id等信息,直接通过Lua脚本等技术来访问缓存中的库存信息。如果秒杀商品的库存小于或者等于0,则直接返回用户商品已售完的提示信息,而不用再经过应用层的层层校验了。 针对这个架构,我们可以参见本文中的电商系统的架构图(正文开始的第一张图)。
Redis助力秒杀系统
我们可以在Redis中设计一个Hash数据结构,来支持商品库存的扣减操作,如下所示。
seckill:goodsStock:${goodsId}{
totalCount:200,
initStatus:0,
seckillCount:0}在我们设计的Hash数据结构中,有三个非常主要的属性。
totalCount:表示参与秒杀的商品的总数量,在秒杀活动开始前,我们就需要提前将此值加载到Redis缓存中。
initStatus:我们把这个值设计成一个布尔值。秒杀开始前,这个值为0,表示秒杀未开始。可以通过定时任务或者后台操作,将此值修改为1,则表示秒杀开始。
seckillCount:表示秒杀的商品数量,在秒杀过程中,此值的上限为totalCount,当此值达到totalCount时,表示商品已经秒杀完毕。
我们可以通过下面的代码片段在秒杀预热阶段,将要参与秒杀的商品数据加载的缓存。
/**
* @author binghe
* @description 秒杀前构建商品缓存代码示例
*/public class SeckillCacheBuilder{
private static final String GOODS_CACHE = "seckill:goodsStock:";
private String getCacheKey(String id) {
return GOODS_CACHE.concat(id);
}
public void prepare(String id, int totalCount) {
String key = getCacheKey(id);
Map<String, Integer> goods = new HashMap<>();
goods.put("totalCount", totalCount);
goods.put("initStatus", 0);
goods.put("seckillCount", 0);
redisTemplate.opsForHash().putAll(key, goods);
}}秒杀开始的时候,我们需要在代码中首先判断缓存中的seckillCount值是否小于totalCount值,如果seckillCount值确实小于totalCount值,我们才能够对库存进行锁定。在我们的程序中,这两步其实并不是原子性的。如果在分布式环境中,我们通过多台机器同时操作Redis缓存,就会发生同步问题,进而引起“超卖”的严重后果。
在电商领域,有一个专业名词叫作“超卖”。顾名思义:“超卖”就是说卖出的商品数量比商品的库存数量多,这在电商领域是一个非常严重的问题。那么,我们如何解决“超卖”问题呢?
Lua脚本完美解决超卖问题
我们如何解决多台机器同时操作Redis出现的同步问题呢?一个比较好的方案就是使用Lua脚本。我们可以使用Lua脚本将Redis中扣减库存的操作封装成一个原子操作,这样就能够保证操作的原子性,从而解决高并发环境下的同步问题。
例如,我们可以编写如下的Lua脚本代码,来执行Redis中的库存扣减操作。
local resultFlag = "0" local n = tonumber(ARGV[1]) local key = KEYS[1] local goodsInfo = redis.call("HMGET",key,"totalCount","seckillCount") local total = tonumber(goodsInfo[1]) local alloc = tonumber(goodsInfo[2]) if not total then
return resultFlag
end
if total >= alloc + n then
local ret = redis.call("HINCRBY",key,"seckillCount",n)
return tostring(ret) end
return resultFlag我们可以使用如下的Java代码来调用上述Lua脚本。
public int secKill(String id, int number) {
String key = getCacheKey(id);
Object seckillCount = redisTemplate.execute(script, Arrays.asList(key), String.valueOf(number));
return Integer.valueOf(seckillCount.toString()); }这样,我们在执行秒杀活动时,就能够保证操作的原子性,从而有效的避免数据的同步问题,进而有效的解决了“超卖”问题。
为了应对秒杀系统高并发大流量的业务场景,除了秒杀系统本身的业务架构外,我们还要进一步优化服务器硬件的性能,接下来,我们就一起来看一下如何优化服务器的性能。
优化服务器性能
操作系统
这里,我使用的操作系统为CentOS 8,我们可以输入如下命令来查看操作系统的版本。
CentOS Linux release 8.0.1905 (Core)
对于高并发的场景,我们主要还是优化操作系统的网络性能,而操作系统中,有很多关于网络协议的参数,我们对于服务器网络性能的优化,主要是对这些系统参数进行调优,以达到提升我们应用访问性能的目的。
系统参数
在CentOS 操作系统中,我们可以通过如下命令来查看所有的系统参数。
/sbin/sysctl -a
部分输出结果如下所示。
这里的参数太多了,大概有一千多个,在高并发场景下,我们不可能对操作系统的所有参数进行调优。我们更多的是关注与网络相关的参数。如果想获得与网络相关的参数,那么,我们首先需要获取操作系统参数的类型,如下命令可以获取操作系统参数的类型。
/sbin/sysctl -a|awk -F "." '{print $1}'|sort -k1|uniq运行命令输出的结果信息如下所示。
abi crypto debug dev fs kernel net sunrpc user vm
其中的net类型就是我们要关注的与网络相关的操作系统参数。我们可以获取net类型下的子类型,如下所示。
/sbin/sysctl -a|grep "^net."|awk -F "[.| ]" '{print $2}'|sort -k1|uniq输出的结果信息如下所示。
bridge core ipv4 ipv6 netfilter nf_conntrack_max unix
在Linux操作系统中,这些与网络相关的参数都可以在/etc/sysctl.conf 文件里修改,如果/etc/sysctl.conf 文件中不存在这些参数,我们可以自行在/etc/sysctl.conf 文件中添加这些参数。
在net类型的子类型中,我们需要重点关注的子类型有:core和ipv4。
优化套接字缓冲区
如果服务器的网络套接字缓冲区太小,就会导致应用程序读写多次才能将数据处理完,这会大大影响我们程序的性能。如果网络套接字缓冲区设置的足够大,从一定程度上能够提升我们程序的性能。
我们可以在服务器的命令行输入如下命令,来获取有关服务器套接字缓冲区的信息。
/sbin/sysctl -a|grep "^net."|grep "[r|w|_]mem[_| ]"
输出的结果信息如下所示。
net.core.rmem_default = 212992net.core.rmem_max = 212992net.core.wmem_default = 212992net.core.wmem_max = 212992net.ipv4.tcp_mem = 43545 58062 87090net.ipv4.tcp_rmem = 4096 87380 6291456net.ipv4.tcp_wmem = 4096 16384 4194304net.ipv4.udp_mem = 87093 116125 174186net.ipv4.udp_rmem_min = 4096net.ipv4.udp_wmem_min = 4096
其中,带有max、default、min关键字的为分别代表:最大值、默认值和最小值;带有mem、rmem、wmem关键字的分别为:总内存、接收缓冲区内存、发送缓冲区内存。
这里需要注意的是:带有rmem 和 wmem关键字的单位都是“字节”,而带有mem关键字的单位是“页”。“页”是操作系统管理内存的最小单位,在 Linux 系统里,默认一页是 4KB 大小。
如何优化频繁收发大文件
如果在高并发场景下,需要频繁的收发大文件,我们该如何优化服务器的性能呢?
这里,我们可以修改的系统参数如下所示。
net.core.rmem_default net.core.rmem_max net.core.wmem_default net.core.wmem_max net.ipv4.tcp_mem net.ipv4.tcp_rmem net.ipv4.tcp_wmem
这里,我们做个假设,假设系统最大可以给TCP分配 2GB 内存,最小值为 256MB,压力值为 1.5GB。按照一页为 4KB 来计算, tcp_mem 的最小值、压力值、最大值分别是 65536、393216、524288,单位是“页” 。
假如平均每个文件数据包为 512KB,每个套接字读写缓冲区最小可以各容纳 2 个数据包,默认可以各容纳 4 个数据包,最大可以各容纳 10 个数据包,那我们可以算出 tcp_rmem 和 tcp_wmem 的最小值、默认值、最大值分别是 1048576、2097152、5242880,单位是“字节”。而 rmem_default 和 wmem_default 是 2097152,rmem_max 和 wmem_max 是 5242880。
注:后面详细介绍这些数值是如何计算的~~
这里,还需要注意的是:缓冲区超过了 65535,还需要将 net.ipv4.tcp_window_scaling 参数设置为 1。
经过上面的分析后,我们最终得出的系统调优参数如下所示。
net.core.rmem_default = 2097152net.core.rmem_max = 5242880net.core.wmem_default = 2097152net.core.wmem_max = 5242880net.ipv4.tcp_mem = 65536 393216 524288net.ipv4.tcp_rmem = 1048576 2097152 5242880net.ipv4.tcp_wmem = 1048576 2097152 5242880
优化TCP连接
对计算机网络有一定了解的小伙伴都知道,TCP的连接需要经过“三次握手”和“四次挥手”的,还要经过慢启动、滑动窗口、粘包算法等支持可靠性传输的一系列技术支持。虽然,这些能够保证TCP协议的可靠性,但有时这会影响我们程序的性能。
那么,在高并发场景下,我们该如何优化TCP连接呢?
(1)关闭粘包算法
如果用户对于请求的耗时很敏感,我们就需要在TCP套接字上添加tcp_nodelay参数来关闭粘包算法,以便数据包能够立刻发送出去。此时,我们也可以设置net.ipv4.tcp_syncookies的参数值为1。
(2)避免频繁的创建和回收连接资源
网络连接的创建和回收是非常消耗性能的,我们可以通过关闭空闲的连接、重复利用已经分配的连接资源来优化服务器的性能。重复利用已经分配的连接资源大家其实并不陌生,像:线程池、数据库连接池就是复用了线程和数据库连接。
我们可以通过如下参数来关闭服务器的空闲连接和复用已分配的连接资源。
net.ipv4.tcp_tw_reuse = 1net.ipv4.tcp_tw_recycle = 1net.ipv4.tcp_fin_timeout = 30net.ipv4.tcp_keepalive_time=1800
(3)避免重复发送数据包
TCP支持超时重传机制。如果发送方将数据包已经发送给接收方,但发送方并未收到反馈,此时,如果达到设置的时间间隔,就会触发TCP的超时重传机制。为了避免发送成功的数据包再次发送,我们需要将服务器的net.ipv4.tcp_sack参数设置为1。
(4)增大服务器文件描述符数量
在Linux操作系统中,一个网络连接也会占用一个文件描述符,连接越多,占用的文件描述符也就越多。如果文件描述符设置的比较小,也会影响我们服务器的性能。此时,我们就需要增大服务器文件描述符的数量。
例如:fs.file-max = 10240000,表示服务器最多可以打开10240000个文件。
来源:实践出真知:全网最强秒杀系统架构解密,不是所有的秒杀都是秒杀!!-云社区-华为云 (huaweicloud.com)
声明:本站所有内容均为自动采集而来,如有侵权,请联系删除